25 Matching
This is the published R edition of the book. A Python version of the book is available at era_pl_book.
In Chapter 4, we discussed three basic causal diagrams and suggested that the concept of nonparametric conditioning on \(Z\) is more demanding than simply including \(Z\) as another regressor in a linear regression model. This chapter develops this idea more fully and examines practical approaches to properly conditioning on confounding variables.
The code in this chapter uses the packages listed below. We load tidyverse because we use several packages from the Tidyverse. For instructions on how to set up your computer to use the code found in this book, see Section 1.2. Quarto templates for the exercises below are available on GitHub.
25.1 Background on auditor choice
For concreteness, we will explore the basic ideas of this chapter using the setting of auditor choice and its effects. An extensive literature has examined the question of whether “Big N” auditors produce higher audit quality. This question is examined in two of the papers we will study in this chapter (DeFond et al., 2017; Lawrence et al., 2011).
For data on auditors, the table comp.funda has a column labelled au, which lines up with aucd in comp.r_auditors.
db <- dbConnect(duckdb::duckdb())
company <- load_parquet(db, schema = "comp", table = "company")
funda <- load_parquet(db, schema = "comp", table = "funda")
r_auditors <- load_parquet(db, schema = "comp", table = "r_auditors")When Lawrence et al. (2011) refer to the “Big Four”, they are actually referring to the current group that DeFond et al. (2017) refer to as the “Big N”. The latter term alludes to the prior incarnations of the set of top audit firms, including the “Big Five” (prior to the demise of Arthur Andersen) and the “Big Eight” (prior to mergers in the late 1980s) (see Gow and Kells, 2018 for more on this history).
aucd for top auditors
| aucd | audesc |
|---|---|
| 0 | Unaudited |
| 1 | Arthur Andersen |
| 2 | Arthur Young |
| 3 | Coopers & Lybrand |
| 4 | Ernst & Young |
| 5 | Deloitte & Touche |
| 6 | KPMG |
| 7 | PricewaterhouseCoopers |
| 8 | Touche Ross |
| 9 | Other |
| 10 | Altschuler, Melvoin, and Glasser |
| 11 | BDO |
Looking closer at a sample from r_auditors in Table 25.1, we see that Arthur Andersen has an aucd of 1. Note that Arthur Young is now part of Ernst & Young, Coopers & Lybrand is now part of PricewaterhouseCoopers, and Touche Ross is now part of Deloitte & Touche. So a reasonable approach to “Big N” would appear to be big4 = aucd %in% 1:8L.1 It’s commonly understood that most large firms choose a Big Four auditor. But rather than simply accepting that, we can look at the data.
Here we focus on firms with meaningful financial statements (sale > 0, at > 0) and fiscal 2019, the latest fiscal year with complete data at the time of first writing this chapter.
size_big4 <-
funda |>
filter(indfmt == "INDL", datafmt == "STD",
consol == "C", popsrc == "D") |>
filter(sale > 0, at > 0, fyear == 2019, !is.na(au)) |>
mutate(au = as.integer(au)) |>
select(gvkey, datadate, fyear, au, prcc_f, csho) |>
mutate(big4 = au %in% 1:8L,
mkt_cap = prcc_f * csho * 1e6) |>
arrange(gvkey, datadate) |>
collect()We calculate market share by “bins” where each bin represents an order of magnitude of market capitalization and show statistics for each bin in Table 25.2. For example, (9, 10] includes all firms with market capitalization over $1 billion (\(10^9\)) and less than or equal to $10 billion (\(10^{10}\)).
| bin | big4_perc | big4_num | non_big4_num |
|---|---|---|---|
| (6,7] | 16.32 | 63 | 323 |
| (7,8] | 27.59 | 338 | 887 |
| (8,9] | 58.06 | 1052 | 760 |
| (9,10] | 89.68 | 1581 | 182 |
| (10,11] | 96.76 | 687 | 23 |
| (11,12] | 97.85 | 91 | 2 |
| (12,13] | 100.00 | 1 | 0 |
Interestingly, one of the two cases of companies with an apparent market capitalization over $100 billion (\(10^{11}\)) and a non–Big Four auditor is Vanjia, which apparently misstated the number of its shares outstanding as 8,550 million rather than 30 million.2
size_big4 |>
filter(!big4, mkt_cap > 1e11) |>
mutate(fyear = as.character(fyear))| gvkey | datadate | fyear | au | prcc_f | csho | big4 | mkt_cap |
|---|---|---|---|---|---|---|---|
| 014447 | 2019-12-31 | 2019 | 9 | 92.988 | 2,518.262 | FALSE | 234,168,146,856 |
| 026478 | 2019-12-31 | 2019 | 9 | 14.380 | 8,550.000 | FALSE | 122,949,000,000 |
We can also present the data as a histogram. From either Table 25.2 or Figure 25.1, it is clear that the Big Four have overwhelming market share among the largest firms and have most of the market even among firms with market capitalization in the $100 million-to-$1 billion range.
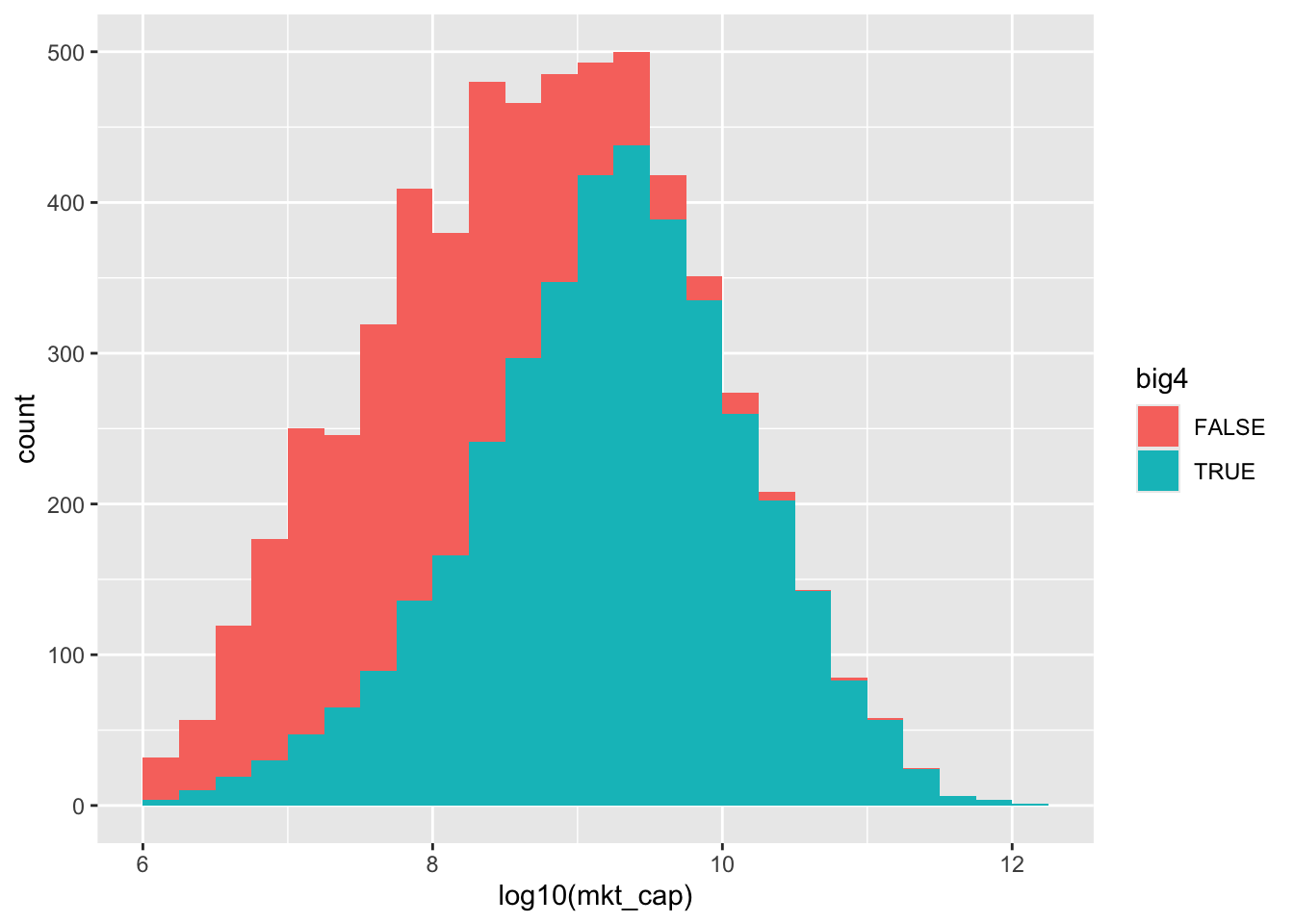
25.2 Simulation analysis
One challenge for an empirical researcher studying the effect of having a Big Four auditor is that market capitalization is plausibly a confounding variable, or confounder, of the kind seen in Figure 4.1. That is, having a large market capitalization is likely to cause—or be associated with variables that cause—firms to choose a Big Four auditor and also to affect a variety of economic outcomes that may be of interest, such as accounting quality. We know from our analysis in Chapter 4 that we want to “control for” confounders but we show here that this is not always as simple as including the confounding variable in OLS regression.
In this section, we use simulation analysis to examine more closely how to control for confounding variables. We start with the actual empirical distribution of market capitalization from the data depicted in the histogram above. For each bin in the histogram depicted in Figure 25.1, we calculate the observed conditional probability of a firm in that bin having a Big Four auditor and store the results in prob_big4.
We then run our simulation. We draw 5,000 firms from this distribution and assign each firm an auditor based on the conditional probabilities calculated above. A critical assumption here is that, conditional on market capitalization, whether a Big Four auditor is chosen is completely random. Finally, we calculate a measure of audit quality that is a non-linear function of market capitalization and a random noise component. We explain the role of pick(everything()) in Chapter 13.
n_firms <- 5000
set.seed(2021)
sim_auditor <-
prob_big4 |>
sample_n(size = n_firms) |>
mutate(rand = runif(nrow(pick(everything()))),
big4 = rand < p_big4,
epsilon = rnorm(nrow(pick(everything()))),
id = 1:nrow(pick(everything()))) |>
mutate(audit_quality = big4 * 0 + mkt_cap^(1/3) * 0.003 + epsilon) |>
select(id, big4, mkt_cap, log_mkt_cap, audit_quality)Given this is a simulation, we know that the correct causal diagram is that shown in Figure 25.2.
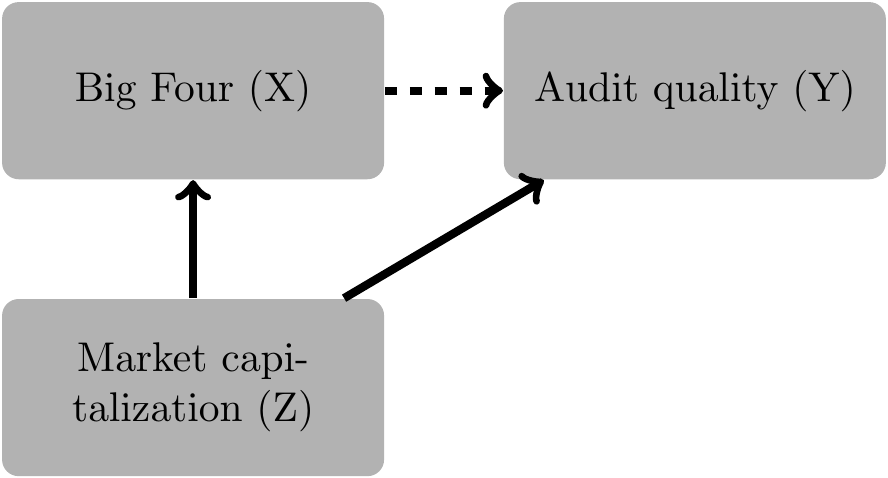
We draw the arrow connecting \(X\) and \(Y\) with a dashed line because the true coefficient on big4 is zero, so in this simulation there is no actual causal relation between big4 and audit_quality. Of course, in reality, we would not know this fact and would need to infer it from data and a posited causal diagram.
The good news from this causal diagram is that correctly conditioning on \(Z\) should give us an unbiased estimator of the causal effect of \(X\) on \(Y\). So let’s regress audit_quality on big4 and mkt_cap.
modelsummary(fm,
estimate = "{estimate}{stars}",
gof_map = c("nobs", "r.squared"),
stars = c('*' = .1, '**' = 0.05, '***' = .01))| (1) | |
|---|---|
| (Intercept) | 1.542*** |
| (0.052) | |
| big4TRUE | 2.398*** |
| (0.066) | |
| I(mkt_cap/1e+09) | 0.053*** |
| (0.001) | |
| Num.Obs. | 5000 |
| R2 | 0.550 |
In Table 25.4, we see a clearly positive coefficient on big4 even though we are “controlling for” mkt_cap, and we might be tempted to conclude that we have identified a causal effect. Of course, we know that this conclusion is invalid. The issue is that we are effectively assuming a linear relation between mkt_cap and audit quality, whereas the true relation is non-linear in mkt_cap. As a result, “controlling for” mkt_cap by including mkt_cap in a regression does not adequately control for the relation between mkt_cap and audit quality. Because there is a non-linear relation between big4 and mkt_cap, the regression specification can use information in big4 to explain variation in audit_quality in addition to that variation explained by a linear function of mkt_cap. This additional explanatory power shows up as a statistically significant coefficient on big4 in the regression above.
Would some kind of matching analysis help?
Given its prominence in accounting research, we will focus on propensity-score matching here. In this section, we present propensity-score matching as a recipe of sorts. We then evaluate how well it does in our simulated settings before discussing some aspects of the theory that explains why (and when) we might expect it to work.
The first step in our recipe is the estimation of propensity scores, which are estimates of the probability of receiving treatment as a function of observed variables. The most common approach is to use logistic regression, which we can do using glm(), as seen in Chapter 23.
We can estimate propensity scores as the fitted values from the estimated logit model (we specify type = "response" to get fitted values on the original \([0, 1]\) scale of the dependent variable).
The second step in the recipe is to match treatment observations to their nearest counterparts among the control observations, where “nearest” means closest in terms of propensity scores. But even with the propensity score, we need an algorithm. To this end, we can use the matchit() function from the MatchIt package. This function returns a matchit object to which we can apply match.data() to retrieve the resulting matches, which we store in sim_matches. Following Lawrence et al. (2011), we use a caliper of 3% and use !big4 as the dependent variable, as not having a Big Four auditor is the less common condition.
sim_matches <-
matchit(!big4 ~ mkt_cap, data = sim_match_pscores, caliper = 0.03) |>
match.data()Warning: glm.fit: fitted probabilities numerically 0 or 1 occurredInspecting sim_matches, we see that it contains the variable distance that exactly matches pscore that we estimated above.
sim_matches |> count(pscore == distance)# A tibble: 1 × 2
`pscore == distance` n
<lgl> <int>
1 TRUE 2298In addition to the original contents of sim_auditor for the matched observations, sim_matches contains data on the matched pairs in the column subclass. Picking observations for three arbitrary values of subclass, we can see in Table 25.5 that each value is associated with a pair of observations, one with big4 == FALSE and one with big4 == TRUE and very similar values of mkt_cap and hence very similar pscore values.
| id | big4 | mkt_cap | pscore | subclass |
|---|---|---|---|---|
| 933 | FALSE | 162,154,720 | 0.529 | 220 |
| 780 | TRUE | 218,727,240 | 0.523 | 220 |
| 1406 | FALSE | 243,446,880 | 0.520 | 333 |
| 4101 | TRUE | 298,323,630 | 0.514 | 333 |
| 2070 | FALSE | 278,466,480 | 0.517 | 481 |
| 3107 | TRUE | 334,883,150 | 0.511 | 481 |
To examine the success of the match, we can compare two pairs of histograms. The first pair of histograms (Figure 25.3) shows the propensity scores for all observations. Here we see that there are many treatment observations with p-scores above say 0.70, but very few control observations with comparable p-scores to match with these. In this relatively simple setting, this is really just another way of saying there are many large Big Four clients and few similarly sized non–Big Four clients to match with them. This suggests that many observations will be unmatched.
The second pair of histograms (Figure 25.4) shows the propensity scores for the matched observations. We can see that the distributions of p-scores for treatment and control observations look very similar, suggesting a fairly good match.
sim_match_pscores |>
ggplot(aes(x = pscore, fill = big4)) +
geom_histogram(binwidth = 0.025) +
facet_grid(big4 ~ .) +
theme(legend.position = "none")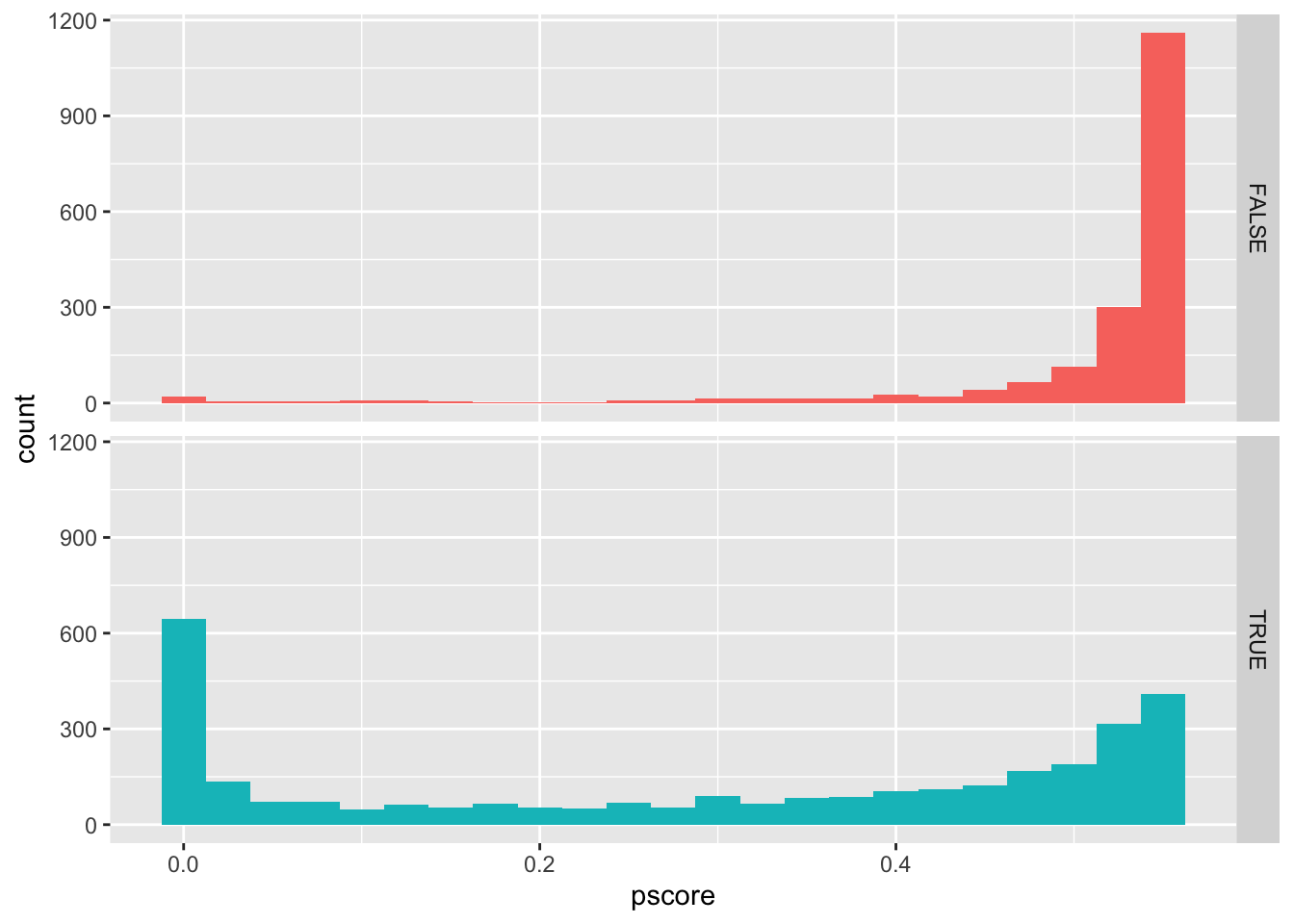
sim_matches |>
ggplot(aes(x = pscore, fill = big4)) +
geom_histogram(binwidth = 0.025) +
facet_grid(big4 ~ .) +
theme(legend.position = "none")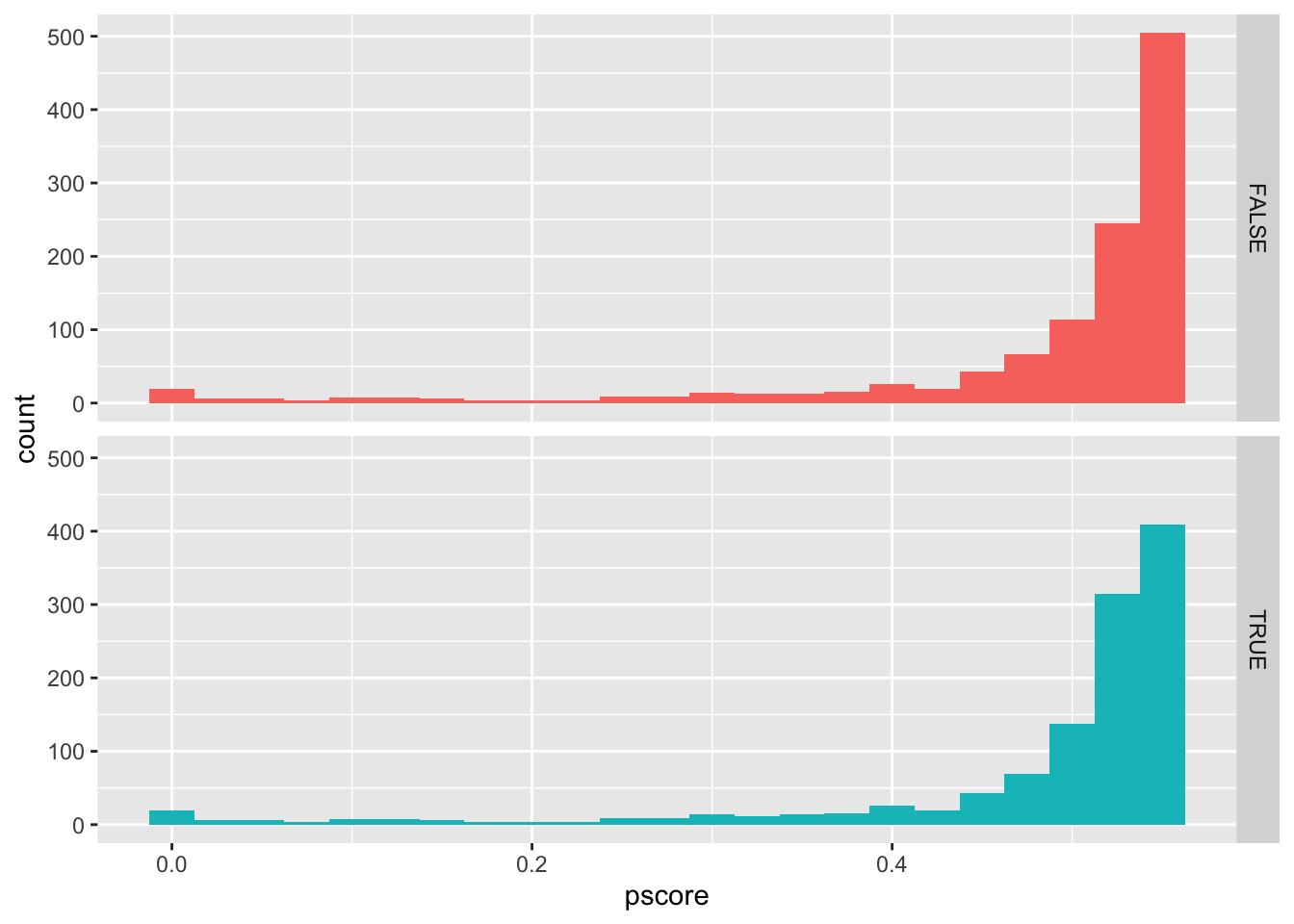
If we are happy with the match, we can finish our analysis by estimating regressions. Like Lawrence et al. (2011), we estimate regressions with and without the variables from the p-score regression (Shipman et al., 2016 refer to these approaches as, respectively, “MR” and “t-test”).
modelsummary(fms,
estimate = "{estimate}{stars}",
gof_map = c("nobs", "r.squared"),
stars = c('*' = .1, '**' = 0.05, '***' = .01))big4 and audit quality (matched)
| (1) | (2) | |
|---|---|---|
| (Intercept) | 1.872*** | 1.788*** |
| (0.051) | (0.046) | |
| big4TRUE | 0.233*** | 0.218*** |
| (0.073) | (0.064) | |
| I(mkt_cap/1e+09) | 0.083*** | |
| (0.003) | ||
| Num.Obs. | 2298 | 2298 |
| R2 | 0.004 | 0.215 |
Interestingly, in Table 25.6, we see that big4 still has a statistically significant relation with audit quality. This is likely due to a residual effect of mkt_cap being picked up by big4 due to the imperfection of the propensity-score match.
25.2.1 Exercises
What happens in the above analyses if the true effect of
big4on audit quality is10instead of0?What happens in the above analyses if the caliper is reduced to
0.01from0.03(but the true effect ofbig4on audit quality is still0)?What happens in the above analyses if the caliper is reduced to
0.01from0.03and the true effect ofbig4on audit quality is10?Given the above, what are your conclusions about the value of propensity-score matching and OLS in causal inference?
What regression results do you get if you repeat the analysis shown in Table 25.4, but replace
I(mkt_cap / 1e+09)withI(mkt_cap^(1/3) * 0.003)? Does this suggest a solution to the issues we see above? If so, what challenges does such a solution face?Was endogeneity an issue in the simulation above? If not, why not? If so, in what way, and what could you do to address it?
25.3 Replication of Lawrence et al. (2011)
To facilitate discussion, we conduct an approximate replication of Lawrence et al. (2011) and begin by constructing a subset of Compustat with calculations used in that paper.
comp <-
funda |>
filter(indfmt == "INDL", datafmt == "STD",
consol == "C", popsrc == "D") |>
filter(!is.na(sich), !between(sich, 6000, 6999),
sale > 0, at > 0,
(dltt >= 0 | is.na(dltt)) & (dlc >= 0 | is.na(dlc)),
prcc_f * csho > 0, ceq > 0) |>
select(gvkey, datadate, fyear, au, prcc_f, csho, at, ib,
dltt, dlc, rect, ppent, sale, act, lct, sich,
oancf) |>
mutate(sic2 = floor(sich / 100)) |>
filter(between(fyear, 1988, 2006)) |>
group_by(gvkey) |>
window_order(fyear) |>
mutate(lag_fyear = lag(fyear),
avg_at = (lag(at) + at) / 2,
log_at = log(at),
aturn = if_else(lag(at) > 0, sale / lag(at), NA),
inv_avg_at = 1 / avg_at,
d_sale = sale - lag(sale),
d_rect = rect - lag(rect),
d_sale_at = (d_sale - d_rect) / avg_at,
ppe_at = ppent / avg_at,
curr = if_else(lct > 0, act / lct, NA),
lag_curr = lag(curr),
lev = if_else(avg_at > 0,
(dltt + coalesce(dlc, 0)) / avg_at, NA),
lag_lev = lag(lev),
roa = if_else(avg_at > 0, ib / avg_at, NA),
lag_roa = lag(roa),
accruals = ib - oancf,
ta = accruals / avg_at,
mkt_cap = prcc_f * csho,
log_mkt = if_else(mkt_cap > 0, log(mkt_cap), NA)) |>
ungroup() |>
filter(lag_fyear == fyear - 1) |>
collect()Lawrence et al. (2011) estimate discretionary accrual models by industry and year, subject to a requirement of at least 10 data points for each model. So we compile a list of industry-years that meet this criterion.
We next construct a function to estimate discretionary accruals along the lines described in footnote 11 of Lawrence et al. (2011). Because we self-join the results data frame created in this function in a way that results in multiple matches for each observation, we specify relationship = "many-to-many". As we did in Chapter 14, we use !! to distinguish the values sic2 and fyear supplied to the function from the variables found in comp.3
get_klw_data <- function(sic2, fyear, ...) {
reg_data <-
comp |>
filter(sic2 == !!sic2, fyear == !!fyear)
fm <- tryCatch(lm(ta ~ inv_avg_at + d_sale_at + ppe_at,
data = reg_data, na.action = na.exclude),
error = function(e) NULL)
if (is.null(fm)) return(NULL)
results <-
reg_data |>
select(gvkey, fyear, roa) |>
bind_cols(da = resid(fm)) |>
filter(!is.na(da))
results |>
inner_join(results, by = "fyear",
suffix = c("", "_match"),
relationship = "many-to-many") |>
filter(gvkey != gvkey_match) |>
mutate(roa_diff = abs(roa - roa_match)) |>
group_by(gvkey, fyear) |>
filter(roa_diff == min(roa_diff, na.rm = TRUE)) |>
ungroup() |>
mutate(ada = abs(da - da_match)) |>
select(gvkey, fyear, da, ada)
}We can then pmap() this function onto industries, our set of industry-years and store the results in klw_results.4
We first estimate an OLS regression using the full sample and raw (i.e., unwinsorized) data and store it in a list named fms.
full_sample <-
comp |>
inner_join(klw_results, by = c("gvkey", "fyear")) |>
filter(avg_at > 0) |>
mutate(big4 = au %in% 1:8L,
mkt_cap = prcc_f * csho,
log_mkt = if_else(mkt_cap > 0, log(mkt_cap), NA))
fms <- list("OLS" = feols(ada ~ big4 + log_mkt + lag_roa +
lag_lev + lag_curr | sic2 + fyear,
data = full_sample))Lawrence et al. (2011) winsorize several variables in their analysis. We use the winsorize() function from the farr package to do this here.5 We then fit a model using the winsorized data and store it in fms.
win_vars <- c("ada", "log_mkt", "lag_roa", "lag_lev", "lag_curr",
"roa", "lev", "curr", "mkt_cap")
full_sample_win <-
full_sample |>
mutate(across(all_of(win_vars),
\(x) winsorize(x, prob = 0.01)))
fms[["OLS, win"]] <-
feols(ada ~ big4 + log_mkt + lag_roa + lag_lev + lag_curr |
sic2 + fyear,
~ gvkey + fyear,
data = full_sample_win)We next create a matched samples using propensity-score matching. Following Lawrence et al. (2011), we discard matches where the difference in p-scores is greater than 3%. First, we match using the raw data and estimate a model using this matched sample.
lmz_match <-
full_sample |>
filter(if_all(c(log_at, log_mkt, aturn, curr, lev, roa),
\(x) !is.na(x))) |>
matchit(!big4 ~ log_at + log_mkt + aturn +
curr + lev + roa,
data = _,
caliper = 0.0300, std.caliper = FALSE,
m.order = "largest", discard = "both")
fms[["PSM"]] <-
lmz_match |>
match.data() |>
feols(ada ~ big4 + log_mkt + lag_roa + lag_lev + lag_curr |
sic2 + fyear, ~ gvkey + fyear,
data = _)Second, we match using the winsorized data and estimate a model using the matched sample.
lmz_match_win <-
full_sample_win |>
filter(if_all(c(log_at, log_mkt, aturn, curr, lev, roa),
\(x) !is.na(x))) |>
matchit(!big4 ~ log_at + log_mkt + aturn + curr + lev + roa,
data = _,
caliper = 0.0300, std.caliper = FALSE,
m.order = "largest", discard = "both")
lmz_matched_win <- match.data(lmz_match_win)
fms[["PSM, win"]] <-
feols(ada ~ big4 + log_mkt + lag_roa + lag_lev + lag_curr |
sic2 + fyear,
~ gvkey + fyear,
data = lmz_matched_win)Regression results from all four models are shown in Table 25.7.
modelsummary(fms,
estimate = "{estimate}{stars}",
gof_map = c("nobs", "r.squared"),
stars = c('*' = .1, '**' = 0.05, '***' = .01))| OLS | OLS, win | PSM | PSM, win | |
|---|---|---|---|---|
| big4TRUE | -0.016*** | -0.014*** | -0.007*** | -0.006*** |
| (0.001) | (0.001) | (0.002) | (0.002) | |
| log_mkt | -0.006*** | -0.005*** | -0.007*** | -0.006*** |
| (0.000) | (0.000) | (0.001) | (0.001) | |
| lag_roa | -0.108*** | -0.124*** | -0.109*** | -0.136*** |
| (0.002) | (0.005) | (0.017) | (0.005) | |
| lag_lev | -0.045*** | -0.045*** | -0.055*** | -0.053*** |
| (0.003) | (0.002) | (0.005) | (0.005) | |
| lag_curr | -0.000** | -0.001*** | -0.000 | -0.001* |
| (0.000) | (0.000) | (0.000) | (0.000) | |
| Num.Obs. | 72995 | 72995 | 24218 | 24223 |
| R2 | 0.127 | 0.150 | 0.114 | 0.134 |
25.4 DeFond et al. (2017)
DeFond et al. (2017) re-examine the question of Lawrence et al. (2011), but with some differences in approach.
The first set of differences relates to design choices in the application of propensity-score matching. While Lawrence et al. (2011) focus on a single propensity-score model with five primary covariates, DeFond et al. (2017) augment the propensity-score model with twenty additional variables, namely the squares and cubes of these covariates and the ten interactions between the five covariates. DeFond et al. (2017) then select 1,500 random subsets from the twenty variables to develop propensity-score models. For each estimated propensity-score model, the caliper is set at a random value (less than 30%) that yields a “balanced matched sample”.
A second design-choice variation that DeFond et al. (2017) consider is matching with replacement. While Lawrence et al. (2011) focus on matching one treatment observation with (at most) one control observation without replacement (i.e., once a control observation is matched to a treatment observation, it is not available to match with another treatment observation), DeFond et al. (2017) consider matches with replacement and consider matches where each treatment observation is matched to one, two, or three control firms.
The second set of differences between DeFond et al. (2017) and Lawrence et al. (2011) relates to the measures of audit quality considered. Lawrence et al. (2011) consider cost of equity capital and analyst forecast accuracy, while DeFond et al. (2017) omit these two measures on the basis that they have “poor construct validity, and as a result are rarely used in the prior literature” (DeFond et al., 2017, p. 3637). Instead, DeFond et al. (2017) consider three other measures of audit quality: income-increasing discretionary accruals, restatements, and going concern opinions.
25.5 Further reading
The goal of this chapter was to provide a quick introduction to matching and show what matching can and cannot do. Perhaps the most important takeaway is that matching is not a panacea for issues arising due to endogenous selection into treatment based on unobservable variables (Shipman et al., 2016).
Cunningham (2021) provides a good introduction to matching with discussion of inverse probability weighting and coarsened exact matching. Guo et al. (2020) provide a book-length treatment of the topic.
We saw in Section 25.2 that, even when selection into treatment is based on observable variables, estimates can be unreliable. Chapter 14 of Huntington-Klein (2021) discusses a number of approaches that can be used to address such cases, including inverse probability weighted regression adjustment and entropy balancing.
25.6 Discussion questions
Given the evidence presented in the simulation, how do you interpret the regression results presented in Table 25.7? How do DeFond et al. (2017) appear to interpret the results?
Referring back to the basic causal relations described in Section 4.2, what is the causal diagram implied by equation (1) and Table 2 of Lawrence et al. (2011)? What variables are in PROXY_CONTROLS for Table 2? Why is LOG_ASSETS not found in Table 2?
Do Lawrence et al. (2011) report results from estimating equation (1)? What happens to the “difference in means” between the Full Sample and the Propensity-Score Matched Sample in Table 1? Does this make sense?
Why do you think the difference in means is still statistically significant for two variables in the Propensity-Score Matched Sample column of Table 1 in Lawrence et al. (2011)? Do you think this is a concern?
Lawrence et al. (2011) evaluate three outcomes as measures of audit quality: discretionary accruals, cost of equity, and analyst forecast accuracy? Evaluate each of these measures. Which do you think is best? What are the strengths and weaknesses of this best measure?
Can you think of other measures of audit quality that might make sense?
Apply the check list of Shipman et al. (2016, pp. 217–218) and the questions in Panels B and C of Table 1 of Shipman et al. (2016) to Lawrence et al. (2011). How do Lawrence et al. (2011) stack up against these?
This appears to be the approach used in DeFond et al. (2017), but whether this lines up with the approach used in Lawrence et al. (2011) is hard to say.↩︎
The higher number can be seen in Vanjia’s 10-Q filing for Q1 2020 (https://go.unimelb.edu.au/rzw8), but appears to have been quietly corrected in Vanjia’s 10-Q filing for Q2 2020 (https://go.unimelb.edu.au/jzw8). The other company is LVMH, the French luxury goods firm, which appears to have been audited in part by Ernst & Young: https://go.unimelb.edu.au/izw8.↩︎
Chapter 19 of Wickham (2019) has more details on this “unquote” operator
!!.↩︎We discuss winsorization and the
winsorize()function in Chapter 24.↩︎