import polars as pl
import pyfixest as pf
from rdrobust import rdrobust
from era_pl import load_data, load_parquet, rdplot22 Regression discontinuity designs
Over the last twenty years or so, the regression discontinuity design (RDD) has seen a dramatic rise in popularity among researchers. Cunningham (2021) documents a rapid increase in the number of papers using RDD after 1999 and attributes its popularity to its ability to deliver causal inferences with “identifying assumptions that are viewed by many as easier to accept and evaluate” than those of other methods. Lee and Lemieux (2010, p. 282) point out that RDD requires “seemingly mild assumptions compared to those needed for other non-experimental approaches … and that causal inferences from RDD are potentially more credible than those from typical ‘natural experiment’ strategies.”
Another attractive aspect of RDD is the availability of quality pedagogical materials explaining its use. The paper by Lee and Lemieux (2010) is a good reference, as are chapters in Cunningham (2021) and Angrist and Pischke (2008). Given the availability of these materials, we have written this chapter as a complementary resource, focusing more on practical issues and applications in accounting research. The goal of this chapter is to provide a gateway for you to either using RDD in your own research (should you find a setting with a discontinuity in a treatment of interest) or in reviewing papers using (or claiming to use) RDD.
A number of phenomena of interest to accounting researchers involve discontinuities. For example, whether an executive compensation plan is approved is a discontinuous function of shareholder support (e.g., Armstrong et al., 2013) and whether a debt covenant is violated is typically a discontinuous function of the realization of accounting ratios. So it is not surprising that RDD has attracted some interest of accounting researchers, albeit in a relatively small number of papers. Unfortunately, it is also not surprising that RDD has not always yielded credible causal inferences in accounting research, as we discuss below.
Tip
The code in this chapter uses the packages listed below. For instructions on how to set up your computer to use this code, go to the support page for this book. The support page also includes Quarto templates for the code and exercises below.
22.2 Fuzzy RDD
Fuzzy RDD applies when the cut-off \(x_0\) is associated not with a sharp change from “no treatment for any” to “treatment for all”, but with a sharp increase in the probability of treatment:
\[ P(D_i = 1 | x_i) = \begin{cases} g_1(x_i) & x_i \geq x_0 \\ g_0(x_i) & x_i < x_0 \end{cases}, \text{ where } g_1(x_0) > g_0(x_0) \]
Note that sharp RDD can be viewed as a limiting case of fuzzy RDD in which \(g_1(x_i) = 1\) and \(g_0(x_i) = 0\).
The best way to understand fuzzy RDD is as instrumental variables meets sharp RDD. Suppose that shifting from just below to \(x_0\) to \(x_0\) or just above increases the probability of treatment by \(\pi\), then \(x_0\) is effectively random in that small range, it has an effect on treatment so long as \(\pi\) is sufficiently different from \(0\), and its only effect on \(y\) over that small range occurs only through its effect on treatment.
We can estimate the effect of treatment, \(\rho\), by noting that
\[ \rho = \lim_{\Delta \to 0} \frac{\mathbb{E}[y_{i} | x_0 \leq x_i < x_0 + \Delta] - \mathbb{E}[y_{i} | x_0 - \Delta < x_i < x_0]}{\mathbb{E}[D_{i} | x_0 \leq x_i < x_0 + \Delta] - \mathbb{E}[D_{i} | x_0 - \Delta < x_i < x_0]} \]
Hoekstra (2009) is an excellent paper for building intuition with regard to fuzzy RDD and we recommend you read it.
22.3 Other issues
One issue with RDD is that the effect estimated is a local estimate (i.e., it relates to observations close to the discontinuity). This effect may be very different from the effect at points away from the discontinuity.
Another critical element of RDD is the bandwidth used in estimation. Gow et al. (2016) encourage researchers using RDD to employ methods that exist to estimate optimal bandwidths and the resulting estimates of effects. Credible results from RDD are likely to be robust to alternative bandwidth specifications.
Finally, one strength of RDD is that the estimated relation is often effectively univariate and easily plotted. As suggested by Lee and Lemieux (2010), it is highly desirable for researchers to plot both the underlying data and the fitted regression functions around the discontinuity. Inspection of the plots in Hoekstra (2009) provides some assurance that the estimated effect is “there”. In contrast, the plots below using data from Bloomfield (2021) seem somewhat less compelling.
22.4 Sarbanes-Oxley Act
The Sarbanes-Oxley Act (SOX), passed by the US Congress in 2002 in the wake of scandals such as Enron and WorldCom, was arguably the most significant shift in financial reporting in recent history. Iliev (2010, p. 1163) writes “the law’s main goal was to improve the quality of financial reporting and increase investor confidence.”
A key element of SOX is section 404 (SOX 404). As discussed in Iliev (2010), SOX 404 generated significant controversy, with particular concerns being expressed about the costs of compliance, especially for smaller firms. In response to such concerns, the SEC required only companies whose public float exceeded $75 million in either 2002, 2003, or 2004 to comply with SOX 404 for fiscal years ending on or after 15 November 2004.3 Smaller companies were not required to submit management reports until fiscal 2007 and these did require auditor attestation until 2010.
Iliev (2010) exploits the discontinuity in treatment around $75 million in public float and RDD to evaluate the effect of SOX 404 on audit fees and earnings management, finding evidence that SOX 404’s required management reports increased audit fees, but reduced earnings management.
Some of these data are included in the iliev_2010 data frame included with the era_pl package.
iliev_2010 = load_data("iliev_2010")
iliev_2010
shape: (7_214, 9)
| gvkey | fyear | fdate | pfdate | pfyear | publicfloat | mr | af | cik |
|---|---|---|---|---|---|---|---|---|
| str | i32 | date | date | i32 | f64 | bool | bool | i32 |
| "028712" | 2001 | 2001-12-31 | 2002-03-21 | 2002 | 21.523 | false | false | 908598 |
| "028712" | 2002 | 2002-12-31 | 2002-06-28 | 2002 | 11.46 | false | false | 908598 |
| "028712" | 2003 | 2003-12-31 | 2003-06-30 | 2003 | 13.931 | false | false | 908598 |
| "028712" | 2004 | 2004-12-31 | 2004-06-30 | 2004 | 68.161 | false | false | 908598 |
| "028712" | 2005 | 2005-12-31 | 2005-06-30 | 2005 | 26.437 | false | false | 908598 |
| … | … | … | … | … | … | … | … | … |
| "013354" | 2001 | 2001-11-30 | 2002-03-13 | 2002 | 124.543557 | false | false | 807707 |
| "013354" | 2002 | 2002-11-30 | 2002-05-30 | 2002 | 168.886196 | false | true | 807707 |
| "013354" | 2003 | 2003-11-30 | 2003-05-30 | 2003 | 159.259586 | false | true | 807707 |
| "013354" | 2004 | 2004-11-30 | 2004-05-28 | 2004 | 244.171332 | true | true | 807707 |
| "013354" | 2005 | 2005-11-30 | 2005-05-31 | 2005 | 265.510375 | true | true | 807707 |
The variables af and mr are indicators for a firm being an accelerated filer and for a firm filing a management report under SOX 404, respectively.
Iliev (2010, p. 1169) explains the criteria for a SOX 404 management report being required as follows:
All accelerated filers with a fiscal year ending on or after November 15, 2004 had to file a MR and an auditor’s attestation of the MR under Section 404. I denote these firms as MR firms. Companies that were not accelerated filers as of their fiscal year ending on or after November 15, 2004 did not have to file an MR in that year (non-MR firms). Those were companies that had a public float under $75 million in their reports for fiscal years 2002 (November 2002 to October 2003), 2003 (November 2003 to October 2004), and 2004 (November 2004 to October 2005).
The code producing the following data frame mr_req_df attempts to encode these requirements.
mr_req_df = (
iliev_2010
.filter(
pl.col("fdate").is_between(
pl.date(2002, 11, 1), pl.date(2005, 10, 31)
)
)
.with_columns(
max_float=pl.col("publicfloat").max().over(["gvkey", "fdate"])
)
.filter(pl.col("fdate") >= pl.date(2004, 11, 15))
.with_columns(mr_required=pl.col("max_float") >= 75)
)Interestingly, as seen in Table 22.1, there appear to be a number of firms that indicated that they were not accelerated filers and did not have to file a management report, despite appearing to meet the criteria.
(
mr_req_df
.filter(pl.col("mr_required"), ~pl.col("mr"), ~pl.col("af"))
.select("cik", "fdate", "pfdate", "publicfloat")
.sort("publicfloat", descending=True)
.head(6)
)
shape: (6, 4)
| cik | fdate | pfdate | publicfloat |
|---|---|---|---|
| i32 | date | date | f64 |
| 1028205 | 2005-06-30 | 2005-08-15 | 279.101648 |
| 29834 | 2004-12-31 | 2005-03-16 | 184.901979 |
| 1085869 | 2004-12-31 | 2005-02-28 | 172.091616 |
| 906780 | 2004-12-31 | 2005-03-01 | 171.662126 |
| 943861 | 2004-12-31 | 2005-03-24 | 168.5346 |
| 1003472 | 2004-12-31 | 2005-03-09 | 141.98528 |
Use the firm with a CIK 1022701 as an example, we see that the values included in iliev_2010 are correct. However, digging into the details of the requirements for accelerated filers suggests that the precise requirement was a float of “$75 million or more as of the last business day of its most recently completed second fiscal quarter.” Unfortunately, this number may differ from the number reported on the first page of the 10-K, introducing possible measurement error in classification based solely on the values in publicfloat. Additionally, there may have been confusion about the precise criteria applicable at the time.
Note that Iliev (2010) uses either the variable mr or (for reasons explained below) public float values from 2002, and so does not rely on a precise mapping from public float values over 2002–2004 to mr in his analysis.
22.4.1 Bloomfield (2021)
The main setting we will use to understand the application of RDD is that of Bloomfield (2021), who predicts that reducing reporting flexibility will lower managers’ ability to obfuscate poor performance, thus lowering risk asymmetry, measured as the extent to which a firm’s returns co-vary more with negative market returns than with positive market returns. Bloomfield (2021, p. 869) uses SOX 404 as a constraint on managers’ ability to obfuscate poor performance and “to justify a causal interpretation” follows Iliev (2010) in using “a regression discontinuity design (‘RDD’) to implement an event study using plausibly exogenous variation in firms’ exposure to the SOX 404 mandate.”
Bloomfield (2021) conducts two primary analyses of the association between SOX 404 adoption and risk asymmetry, which are reported in Tables 2 and 4.
Table 4 reports what Bloomfield (2021) labels the “main analysis”. In that table, Bloomfield (2021, p. 884) “follow[s] Iliev’s [2010] regression discontinuity methodology and use a difference-in-differences design to identify the causal effect of reporting flexibility on risk asymmetry. … [and] use[s] firms’ 2002 public floats—before the threshold announcement—as an instrument for whether or not the firm will become treated at the end of 2004.”
All analyses in Table 4 of Bloomfield (2021) include firm and year fixed effects. Panel B includes firm controls, such as firm age and size, while Panel A omits these controls. Like many papers using such fixed-effect structures, inferences across the two panels are fairly similar and thus here we focus on the analysis of the “full sample” without controls.
To reproduce the result of interest, we start with bloomfield_2021, which is provided in the era_pl package based on data made available by Bloomfield (2021). The data frame bloomfield_2021 contains the fiscal years and PERMCOs for the observations in Bloomfield (2021)’s sample. We then compile data on public floats in 2002, which is the proxy for treatment used in Table 4 of Bloomfield (2021).
bloomfield_2021 = load_data("bloomfield_2021")
float_data = (
iliev_2010
.filter(
pl.col("publicfloat") ==
pl.col("publicfloat").min().over(["gvkey", "fyear"])
)
.filter(pl.col("pfyear").is_in([2002, 2004]))
.group_by("gvkey", "pfyear")
.agg(pl.col("publicfloat").mean().alias("float"))
.pivot(on="pfyear", index="gvkey", values="float")
.select(
"gvkey",
pl.col("2002", "2004").name.prefix("float")
)
)To use the data in float_data we need to link PERMCOs to GVKEYs and use ccm_link to create float_data_linked. To maximize the number of successful matches, we do not condition on link-validity dates.
ccmxpf_lnkhist = load_parquet("ccmxpf_lnkhist", "crsp")
ccm_link = (
ccmxpf_lnkhist
.filter(
pl.col("linktype").is_in(["LC", "LU", "LS"]),
pl.col("linkprim").is_in(["C", "P"]),
)
.rename({"lpermco": "permco"})
.select("gvkey", "permco")
.unique()
.collect()
)
float_data_linked = float_data.join(ccm_link, on="gvkey", how="inner")To help us measure risk asymmetry over the twelve months ending with a firm’s fiscal year-end, we get data on the precise year-end for each firm-year from comp.funda and store it in firm_years. We also collect data on sox as this is also found on comp.funda.
funda = load_parquet("funda", "comp")
funda_mod = (
funda
.filter(
pl.col("indfmt") == "INDL",
pl.col("datafmt") == "STD",
pl.col("consol") == "C",
pl.col("popsrc") == "D",
)
)
firm_years = (
funda_mod
.select("gvkey", "fyear", "datadate", "auopic")
.with_columns(
sox=(
pl.col("auopic").cast(pl.Float64) > 0
).fill_null(False)
)
.select("gvkey", "fyear", "datadate", "sox")
.collect()
)We then link this table with bloomfield_2021 using ccm_link to create risk_asymm_sample, which is simply bloomfield_2021 with datadate replacing fyear.
risk_asymm_sample = (
bloomfield_2021
.join(ccm_link, on="permco", how="inner")
.join(firm_years, on=["fyear", "gvkey"], how="inner")
.select("permco", "datadate")
.unique()
.with_columns(
period_start=(
pl.col("datadate").dt.offset_by("-12mo")
+ pl.duration(days=1)
)
)
)To calculate risk asymmetry using the approach described in Bloomfield (2021), we need data on market returns. Bloomfield (2021, pp. 877–878) “exclude[s] the highest 1% and lowest 1% of market return data. … This trimming procedure improves the reliability of the parameter estimates.”
factors_daily = load_parquet("factors_daily", "ff")
mkt_rets = (
factors_daily
.select("date", "rf", "mktrf")
.collect()
.with_columns(pl.col("mktrf").era.truncate().alias("mktrf"))
.filter(pl.col("mktrf").is_not_null())
)Finally, we calculate risk asymmetry using the approach described in Bloomfield (2021). After calculating the regression statistics (slope and nobs) grouped by sign_ret (and permco and datadate), we pivot the data so that beta_plus and beta_minus appear in the same rows.
dsf = load_parquet("dsf", "crsp")
risk_asymmetry = (
dsf
.join_where(
risk_asymm_sample.lazy(),
pl.col("permco") == pl.col("permco_right"),
pl.col("date") >= pl.col("period_start"),
pl.col("date") <= pl.col("datadate"),
)
.join(mkt_rets.lazy(), on="date", how="inner")
.with_columns(
retrf=pl.col("ret") - pl.col("rf"),
sign_ret=pl.col("mktrf") >= 0,
)
.filter(pl.col("retrf").is_not_null())
.group_by("permco", "datadate", "sign_ret")
.agg(
(pl.cov("retrf", "mktrf") / pl.col("mktrf").var()).alias("slope"),
pl.len().alias("nobs"),
)
.collect()
.pivot(
on="sign_ret",
index=["permco", "datadate"],
values=["slope", "nobs"],
)
.rename({
"slope_false": "beta_minus",
"slope_true": "beta_plus",
"nobs_false": "nobs_minus",
"nobs_true": "nobs_plus",
})
.with_columns(
nobs=pl.sum_horizontal(
pl.col("nobs_minus", "nobs_plus")
.fill_null(0)
)
)
.select(
"permco", "datadate",
"beta_minus", "beta_plus", "nobs"
)
)We combine all the data from above into a single data frame for regression analysis. Bloomfield (2021, p. 878) says that “because of the kurtosis of my estimates, I winsorize \(\hat{\beta}\), \(\hat{\beta}^{+}\), and \(\hat{\beta}^{-}\) at 1% and 99% before constructing my measures of risk asymmetry.”
cutoff = 75
reg_data = (
risk_asymmetry
.join(float_data_linked, on="permco", how="left")
.join(
firm_years.select("gvkey", "datadate", "sox"),
on=["gvkey", "datadate"],
how="left",
)
.with_columns(
treat=(pl.col("float2002") >= cutoff).fill_null(True),
post=pl.col("datadate") >= pl.date(2005, 11, 1),
year=pl.col("datadate").dt.year(),
)
.with_columns(
pl.col("beta_minus", "beta_plus").era.winsorize()
)
.with_columns(risk_asymm=pl.col("beta_minus") - pl.col("beta_plus"))
)We then run two regressions: one with firm and year fixed effects and one without. The former aligns with what Bloomfield (2021) reports in Table 4, while the latter better aligns with the RDD analysis we conduct below.
fms = [
pf.feols("risk_asymm ~ I(treat * post)", data=reg_data, vcov="iid"),
pf.feols(
"risk_asymm ~ I(treat * post) | permco + year",
data=reg_data,
vcov="iid",
),
]
pf.etable(
fms,
signif_code=[0.01, 0.05, 0.1],
coef_fmt="b* \n (se)",
custom_model_stats={"Firm and year FE": ["No", "Yes"]},
)| risk_asymm | ||
|---|---|---|
| (1) | (2) | |
| coef | ||
| I(treat * post) | -0.179*** (0.066) |
-0.328*** (0.1) |
| Intercept | 0.267*** (0.023) |
|
| fe | ||
| year | - | x |
| permco | - | x |
| stats | ||
| Firm and year FE | No | Yes |
| Observations | 1,849 | 1,848 |
| R2 | 0.004 | 0.191 |
| Significance levels: * p < 0.1, ** p < 0.05, *** p < 0.01. Format of coefficient cell: Coefficient (Std. Error) | ||
The results reported above confirm the result reported in Bloomfield (2021). While our estimated coefficient of (\(-0.328\)) is not identical to that in Bloomfield (2021) (\(-0.302\)), it is close to it and has the same sign and similar statistical significance.
However, the careful reader will note that Table 4 presents “event study difference-in-differences results” rather than a conventional RDD analysis. Fortunately, we have the data we need to perform conventional RDD analyses ourselves.
First, we ask whether the 2002 float (float2002) being above or below $75 million is a good instrument for treatment (the variable sox derived from Compustat). This is analogous to producing Figure 1 in Hoekstra (2009), which shows a clear discontinuity in the probability of treatment as the running variable crosses the threshold.
In the case of Bloomfield (2021), we have treatment represented by sox, which is derived from Compustat’s auopic variable. One difference between Iliev (2010) and Bloomfield (2021) is that the data in Iliev (2010) extend only to 2006, while data in the sample used in Table 4 of Bloomfield (2021) extend as late as 2009. This difference between the two papers is potentially significant for the validity of float2002 as an instrument for sox, as whether a firm has public float above the threshold in 2002 is likely to become increasingly less predictive of treatment as time goes on.
reg_data_fs = reg_data.filter(pl.col("post"))
rd_fs_2002 = rdrobust(
reg_data_fs["sox"],
reg_data_fs["float2002"],
c=cutoff,
masspoints="off",
)In the following analysis, we use binned means and the local polynomial fit from rdrobust to reproduce the kind of plot provided by rdplot() in the R version.
rdplot(
reg_data_fs,
y="sox",
x="float2002",
cutoff=cutoff,
masspoints="off",
y_label="SOX 404 report indicator",
x_label="Public float in 2002",
)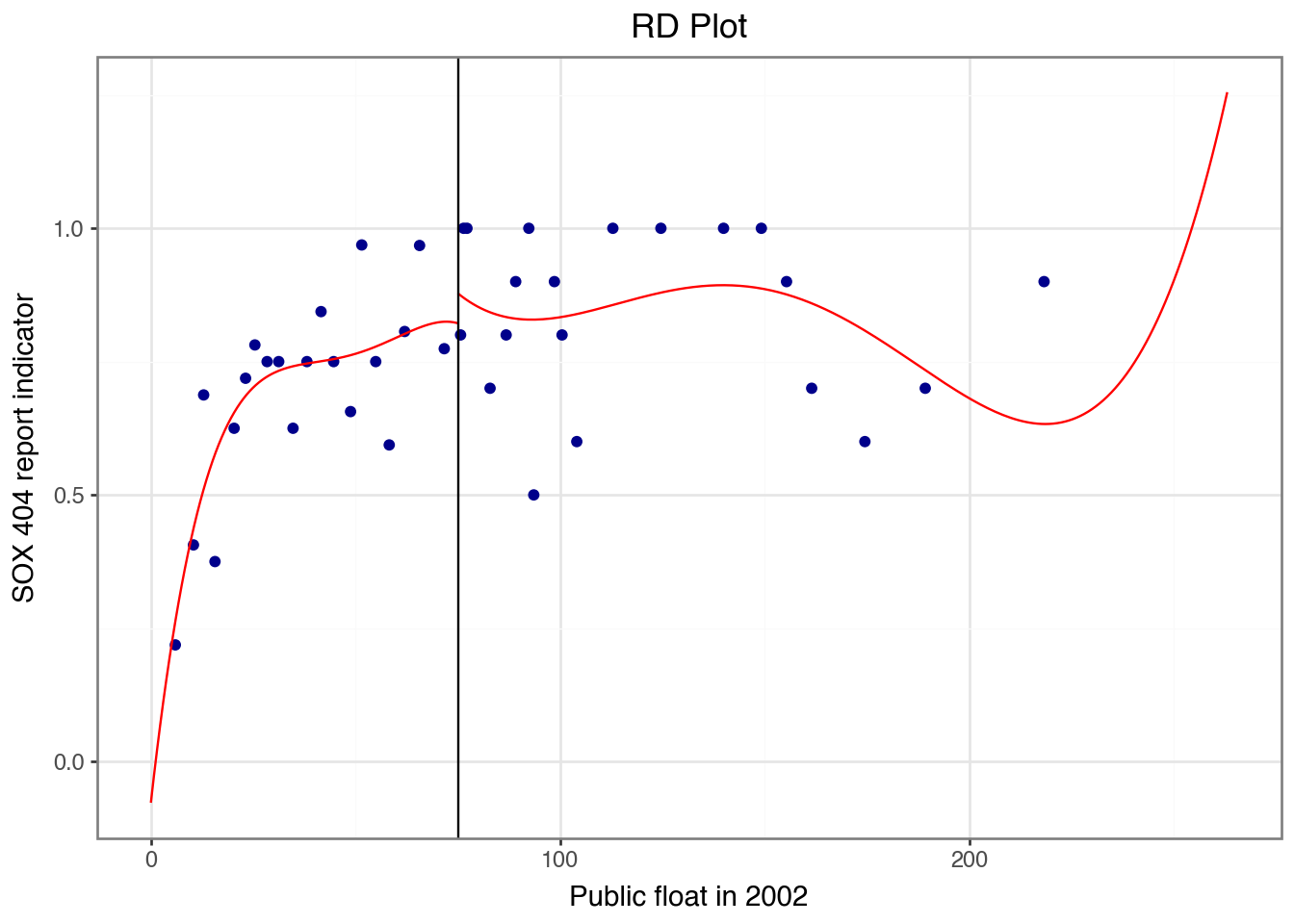
What we observe in Figure 22.1 is that, in contrast to Figure 1 of Hoekstra (2009), there is no obvious discontinuity in the probability of treatment (sox) around the cut-off, undermining the notion that float2002 is a viable instrument for sox.
What happens if we use float2004 as the partitioning variable?
rd_fs = rdrobust(
reg_data_fs["sox"],
reg_data_fs["float2004"],
c=cutoff,
masspoints="off",
)rdplot(
reg_data_fs,
y="sox",
x="float2004",
cutoff=cutoff,
masspoints="off",
y_label="SOX 404 report indicator",
x_label="Public float in 2004",
);From Figure 22.2, we see that things now look a little better and we confirm this statistically next:
rd_fsCall: rdrobust
Number of Observations: 866
Polynomial Order Est. (p): 1
Polynomial Order Bias (q): 2
Kernel: Triangular
Bandwidth Selection: mserd
Var-Cov Estimator: NN
Left Right
------------------------------------------------
Number of Observations 479 387
Number of Unique Obs. 479 387
Number of Effective Obs. 193 154
Bandwidth Estimation 6.988 6.988
Bandwidth Bias 10.036 10.036
rho (h/b) 0.696 0.696
Method Coef. S.E. t-stat P>|t| 95% CI
-------------------------------------------------------------------------
Conventional 0.241 0.065 3.706 2.110e-04 [0.113, 0.368]
Robust - - 3.273 1.063e-03 [0.1, 0.4]The probability jump at the cut-off is \(0.241\) with a standard error of \(0.065\).
This suggests we might run fuzzy RDD with float2004 as the running variable. We can do this using rdrobust() as follows:
rd_ss = rdrobust(
reg_data_fs["risk_asymm"],
reg_data_fs["float2004"],
fuzzy=reg_data_fs["sox"],
c=cutoff,
masspoints="off",
)
rd_ssCall: rdrobust
Number of Observations: 866
Polynomial Order Est. (p): 1
Polynomial Order Bias (q): 2
Kernel: Triangular
Bandwidth Selection: mserd
Var-Cov Estimator: NN
Left Right
------------------------------------------------
Number of Observations 479 387
Number of Unique Obs. 479 387
Number of Effective Obs. 211 169
Bandwidth Estimation 7.834 7.834
Bandwidth Bias 11.961 11.961
rho (h/b) 0.655 0.655
Method Coef. S.E. t-stat P>|t| 95% CI
-------------------------------------------------------------------------
Conventional -0.746 0.678 -1.1 2.714e-01 [-2.075, 0.583]
Robust - - -0.802 4.225e-01 [-2.176, 0.912]The estimated effect at the cut-off is \(-0.746\), which is not significantly different from zero.
We can also run a kind of intent-to-treat RDD as follows and can also plot this as in Figure 22.3.
rd_rf = rdrobust(
reg_data_fs["risk_asymm"],
reg_data_fs["float2004"],
c=cutoff,
masspoints="off",
)
rd_rfCall: rdrobust
Number of Observations: 866
Polynomial Order Est. (p): 1
Polynomial Order Bias (q): 2
Kernel: Triangular
Bandwidth Selection: mserd
Var-Cov Estimator: NN
Left Right
------------------------------------------------
Number of Observations 479 387
Number of Unique Obs. 479 387
Number of Effective Obs. 174 142
Bandwidth Estimation 5.952 5.952
Bandwidth Bias 8.546 8.546
rho (h/b) 0.697 0.697
Method Coef. S.E. t-stat P>|t| 95% CI
-------------------------------------------------------------------------
Conventional -0.202 0.177 -1.145 2.523e-01 [-0.548, 0.144]
Robust - - -0.96 3.373e-01 [-0.601, 0.206]rdplot(
reg_data_fs,
y="risk_asymm",
x="float2004",
cutoff=cutoff,
masspoints="off",
y_label="Risk asymmetry",
x_label="Public float in 2004",
)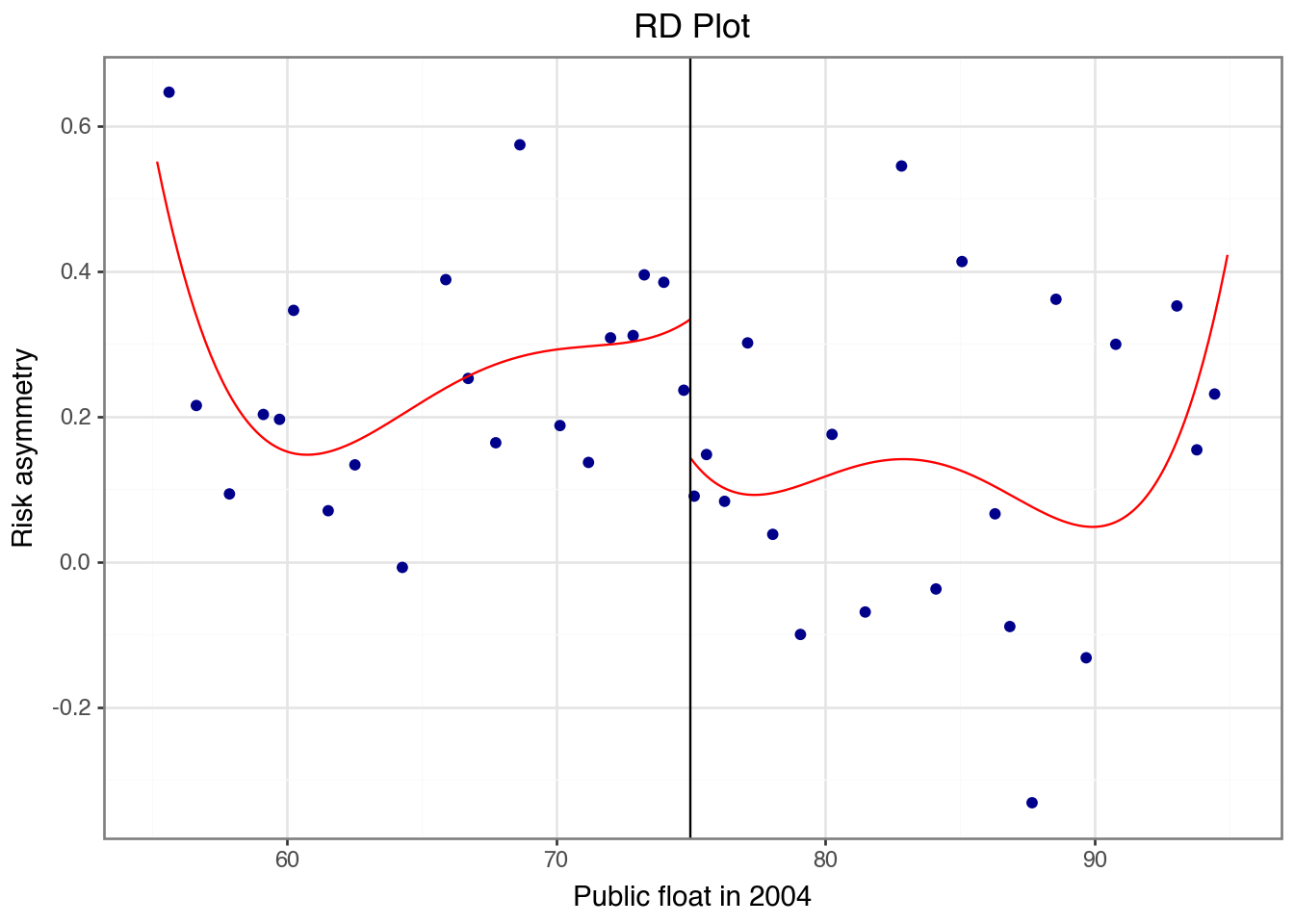
However, in neither the fuzzy RDD nor the intent-to-treat RDD do we reject the null hypothesis of no effect of SOX on risk asymmetry.4
22.5 RDD in accounting research
While RDD has seen an explosion in popularity since the turn of the century, relatively few papers in accounting research have used it. Armstrong et al. (2022) identify seven papers using RDD and we identify an additional five papers not included in their survey, suggesting that papers using RDD represent less than 1% of papers published in top accounting journals since 1999. In this subsection, we examine each of these papers, most of which fall into one of the categories below, to illustrate and discuss how RDD is used in practice in accounting research.
22.5.1 Quasi-RDD
In some settings, RDD would appear to be applicable because there is sharp assignment to treatment based on the realization of a continuous running variable exceeding a pre-determined threshold. For example, debt covenants are often based on accounting-related variables that are continuous, but covenant violation is a discontinuous function of those variables. But a bigger issue in practice is that the running variables are difficult to measure precisely and the thresholds are often not easily observed.
As a result, papers that claim to be “using a regression discontinuity design” simply regress the outcome of interest on a treatment indicator and some controls, perhaps restricting the sample to observations closer to violating covenants. While some have called this quasi-RDD, this is arguably simply not-RDD.
22.5.2 Russell 1000/2000 and stuff (mostly taxes)
Another popular area applying RDD is the burgeoning literature studying the effect of institutional ownership on effective tax rates. Khan et al. (2016), Chen et al. (2019), and Bird and Karolyi (2017) exploit the discontinuous relationship between market capitalization and assignment to either the Russell 1000 or the Russell 2000 index to test for the effect of institutional ownership on tax planning.
Unfortunately, subsequent research shows that the data on index assignments supplied by Russell yielded significant differences in pre-treatment outcome variables on either side of the notional discontinuity.
22.5.3 Other papers using RDD
Kajüter et al. (2018) and Manchiraju and Rajgopal (2017) use RDD in the context of event studies of the classic capital-market kind. Two additional papers in accounting research apply RDD in corporate governance settings. Finally, Figure 1 of Li et al. (2018), which we covered in Chapter 21, presents RDD plots and we include some discussion questions on this analysis below.
22.6 Further reading
As discussed above, this chapter is intended to complement existing materials, and we focus more on practical issues and applications in accounting research. The quality of pedagogical materials for RDD is high. Lee and Lemieux (2010) remains an excellent reference as is Chapter 6 of Angrist and Pischke (2008). Chapter 6 of Cunningham (2021) and Chapter 20 of Huntington-Klein (2021) cover RDD.
22.7 Discussion questions
There are many discussion questions below and we expect that instructors will only assign a subset of these. You should read enough of the papers to be able to answer questions you have been assigned below.
22.7.1 Hoekstra (2009)
What is the treatment in Hoekstra (2009)? What alternative (control) is it being compared with? Is identifying the “treatment” received by the control group always as difficult as it is in Hoekstra (2009)? Provide examples from other papers or settings in your answer.
Which approach makes the most sense in Hoekstra (2009)? Sharp RDD? Or fuzzy RDD? Why?
RDD inherently estimated a “local” treatment effect. Which group of potential students is the focus of Hoekstra (2009)? Can you think of other groups that we might be interested in learning more about? How might the actual treatment effects for those groups differ and why?
22.7.2 Bloomfield (2021)
- Compare the data in
iliev_2010andfloat_datafor the two firms shown in the output below. What choices has Bloomfield (2021) made in processing the data for these two firms? Do these choices seem to be the best ones? If not, what alternative approach could be used?
iliev_2010.filter(pl.col("gvkey") == "001728")
shape: (5, 9)
| gvkey | fyear | fdate | pfdate | pfyear | publicfloat | mr | af | cik |
|---|---|---|---|---|---|---|---|---|
| str | i32 | date | date | i32 | f64 | bool | bool | i32 |
| "001728" | 2001 | 2001-12-31 | 2002-03-01 | 2002 | 96.98183 | false | false | 225051 |
| "001728" | 2002 | 2002-12-31 | 2002-06-28 | 2002 | 69.074991 | false | false | 225051 |
| "001728" | 2003 | 2003-12-31 | 2003-06-27 | 2003 | 71.202402 | false | false | 225051 |
| "001728" | 2005 | 2005-01-01 | 2004-07-03 | 2004 | 105.826661 | true | true | 225051 |
| "001728" | 2005 | 2005-12-31 | 2005-07-01 | 2005 | 87.145568 | true | true | 225051 |
float_data.filter(pl.col("gvkey") == "001728")
shape: (1, 3)
| gvkey | float2002 | float2004 |
|---|---|---|
| str | f64 | f64 |
| "001728" | 83.028411 | null |
iliev_2010.filter(pl.col("gvkey") == "028712")
shape: (5, 9)
| gvkey | fyear | fdate | pfdate | pfyear | publicfloat | mr | af | cik |
|---|---|---|---|---|---|---|---|---|
| str | i32 | date | date | i32 | f64 | bool | bool | i32 |
| "028712" | 2001 | 2001-12-31 | 2002-03-21 | 2002 | 21.523 | false | false | 908598 |
| "028712" | 2002 | 2002-12-31 | 2002-06-28 | 2002 | 11.46 | false | false | 908598 |
| "028712" | 2003 | 2003-12-31 | 2003-06-30 | 2003 | 13.931 | false | false | 908598 |
| "028712" | 2004 | 2004-12-31 | 2004-06-30 | 2004 | 68.161 | false | false | 908598 |
| "028712" | 2005 | 2005-12-31 | 2005-06-30 | 2005 | 26.437 | false | false | 908598 |
float_data.filter(pl.col("gvkey") == "028712")
shape: (1, 3)
| gvkey | float2002 | float2004 |
|---|---|---|
| str | f64 | f64 |
| "028712" | 16.4915 | 68.161 |
The code
treat = (float2002 >= cutoff).fill_null(True)above is intended to replicate Stata code used by Bloomfield (2021):generate treat = float2002 >= 75. Why does the Python/Polars code appear to be more complex? What does Stata do that Python does not do? (Hint: If you don’t have access to Stata, you may find Stata’s documentation helpful.)Bloomfield (2021)’s Stata code for the
postindicator readsgenerate post = fyear - (fyr > 5 & fyr < 11) >= 2005, wherefyearis fiscal year from Compustat andfyrrepresents the month of the fiscal-year end. The code above setspost = datadate >= "2005-11-01". Are the two approaches equivalent? Do we seem to get the right values frompostusing either approach?In the text of the paper, Bloomfield (2021) claims to “use firms’ 2002 public floats … as an instrument for whether or not the firm will become treated” and to “follow Iliev’s [2010] regression discontinuity methodology”. Evaluate each of these claims, providing evidence to support your position.
Bloomfield (2021), inspired by Iliev (2010), uses
float2002rather thanfloat2004as the running variable for treatment. What issues would you be concerned about withfloat2004that might be addressed usingfloat2002? Provide some evidence to test your concerns. What implications do you see for the fuzzy RDD analysis we ran above usingfloat2004as the running variable?Why do you think Bloomfield (2021) did not include RDD analyses along the lines of the ones we have done above in his paper?
In Table 4, Bloomfield (2021, p. 884) uses “a difference-in-differences design to identify the causal effect of reporting flexibility on risk asymmetry.” As we say in Chapter 21, a difference-in-differences estimator adjusts differences in post-treatment outcome values by subtracting differences in pre-treatment outcome values. Why might differences in pre-treatment outcome values between observations on either side of the threshold be particularly problematic in RDD? Does the use of firm and year fixed effects address this problem? Or does it just suppress it?
22.7.3 Boone and White (2015)
What is the treatment in Boone and White (2015)? (Hint: Read the title.) Most of the analyses in the paper use a “sharp RD methodology”. Does this make sense given the treatment? Why or why not?
In Section 5, Boone and White (2015) suggest that while “pre-index assignment firm characteristics are similar around the threshold, one concern is that there could be differences in other unobservable firm factors, leading to a violation of the necessary assumptions for the sharp RD methodology.” Is the absence of “differences in other unobservable firm factors” the requirement for sharp (rather than fuzzy) RD?
What implications, if any, does the discussion on pp. 94–95 of Bebchuk et al. (2017) have for the arguments of Boone and White (2015)?
What is the treatment variable implied by the specification in Equation (1) in Boone and White (2015)?
22.7.4 Manchiraju and Rajgopal (2017)
22.7.5 Ertimur et al. (2015)
Consider Figure 3. How persuasive do you find this plot as evidence of a significant market reaction to majority support in shareholder proposals on majority voting? What aspects of the plot do you find persuasive or unpersuasive?
If shareholders react to successful shareholder proposals on majority voting so positively, why do so many shareholders vote against such proposals?
Ertimur et al. (2015, p. 38) say “our analyses suggest that high votes withheld do not increase the likelihood of a director losing their seat but often cause boards to respond to the governance problems underlying the vote, suggesting that perhaps director elections are viewed by shareholders as a means to obtain specific governance changes rather than a channel to remove a director.” How do you interpret this statement? Do you find it convincing?
22.7.6 Li et al. (2018)
Figure 1 of Li et al. (2018) presents RDD plots. How does the running variable in Figure 1 differ from that in other RDD analyses you have seen? What would you expect to be the relation between the running variable and the outcome variable? Would this vary from the left to the right of the cut-off? Do you agree with the decision of Li et al. (2018, p. 283) to “include high-order polynomials to allow for the possibility of nonlinearity around the cut off time”?
What is the range of values of “distance to IDD adoption” reported in Figure 1? What is the range of possible values given the sample period of Li et al. (2018) and data reported in Appendix B of Li et al. (2018, p. 304)?
Li et al. (2018, p. 283) say that “the figures in both panels show a clear discontinuity at the date of IDD adoption.” Do you agree with this claim?
While Thistlethwaite and Campbell (1960) seems to be very commonly cited as an example of sharp RDD, it appears that only a minority of students who scored higher than the cut-off were awarded National Merit Scholarships, making it strictly an example where fuzzy RDD should be applied if the treatment of interest is receipt of a National Merit Scholarship.↩︎
Hoekstra (2009, p. 719) takes care to explain why this is not a concern in his setting.↩︎
Iliev (2010, p. 1165) describes public float as “the part of equity not held by management or large shareholders, as reported on the first page of the company 10-K.” See also https://www.sec.gov/news/press/2004-158.htm.↩︎
Note that we see even weaker evidence of an effect if we replace
float2004withfloat2002in the intent-to-treat analysis.↩︎