library(DBI)
library(tidyverse)
library(dbplyr)5 Text Analysis
5.1 Why Text Analysis with SQL
I would actually reframe this question as “why store text data in a database?” and offer different reasons from those offered in Tanimura (2021). To structure my answer I will use a representative textual analysis problem (really set of problems) I’ve managed in the past.
Public companies routinely communicate with investors or their representatives through conference calls. Most public companies hold conference calls when they announce their earnings results for a quarter or year. The typical earnings conference call starts with a presentation of results by management, typically the CEO or CEO, followed by the “Q&A” portion of the call during which call participants can ask questions of management Apart from representatives of the company, the typical participant in a conference call is an equity analyst. Equity analysts typically cover a relatively small numbers of companies, typically in a single industry, and provide insights and investment recommendations and related to their covered companies and industries.
Analyst recommendations usually come from valuation analyses that draw on projections of future financial performance. An analyst’s valuation model is usually constructed using a spreadsheet and to some extent an analyst’s questions on a conference call will seek information that can be used for model inputs.
Transcripts of conference calls are collected by a number of data providers, who presumably supply them to various users, including investors and academic researchers. I have used transcripts of conference calls in my own research. The data provider in my case provided a continuous stream of transcripts in XML files. Each call is contained in its own XML file with a file name that indicates the unique identifier of the call. Some elements of the call are contained in structured XML, but the bulk of the data in a call are in a single unstructured XML field.
db <- dbConnect(duckdb::duckdb())
ufo <-
tbl(db, "read_csv_auto('data/ufo*.csv', HEADER=TRUE)") |>
mutate(id = row_number()) |>
compute(name = "ufo")ufo |>
mutate(length = length(sighting_report)) |>
ggplot(aes(x = length)) +
geom_histogram(binwidth = 1)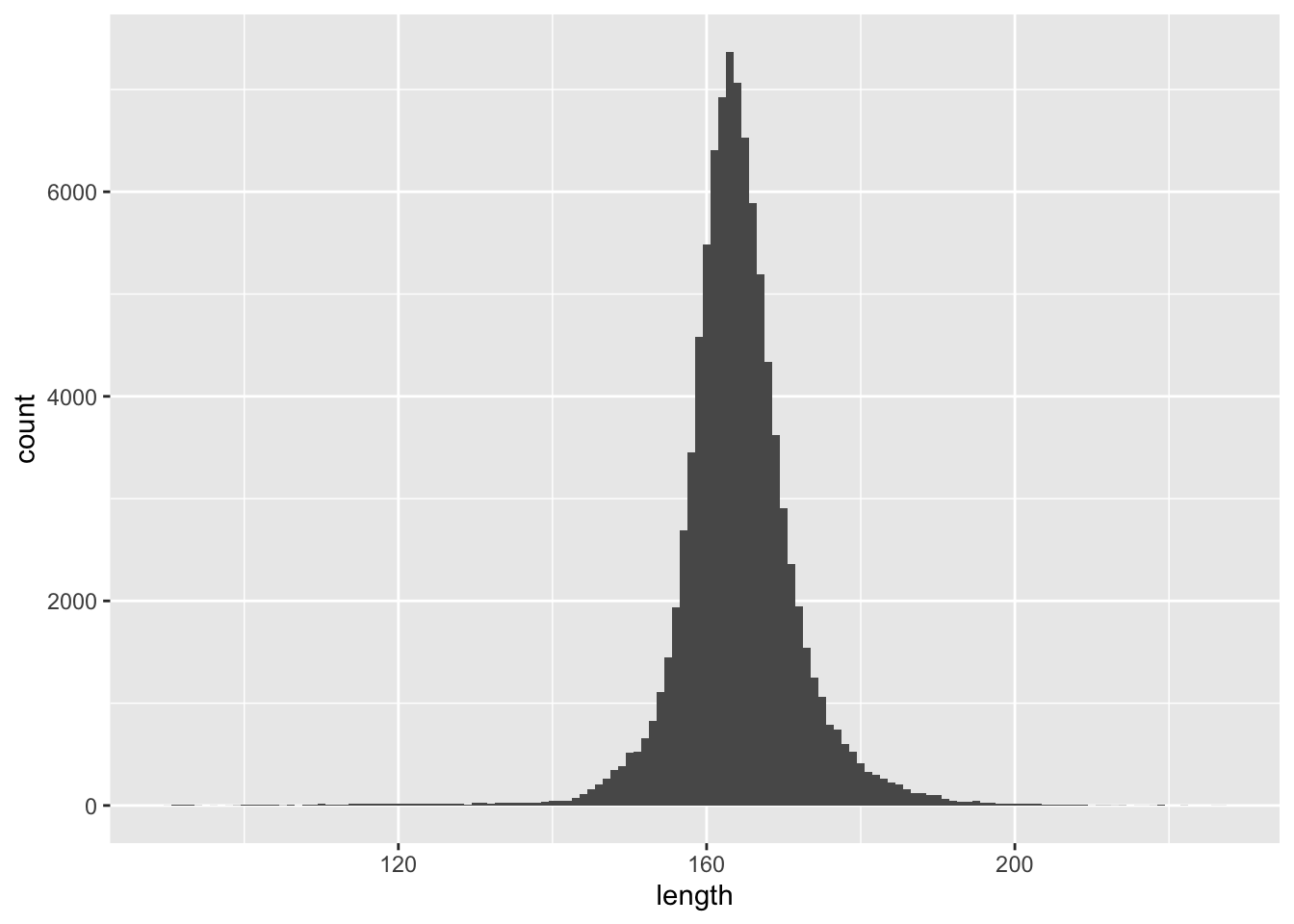
initcap <- function(x) {
if_else(nchar(x) > 0,
paste0(toupper(substr(x, 1, 1)),
tolower(substr(x, 2, nchar(x)))), x)
}ufo %>%
mutate(has_occurred = grepl('Occurred :', sighting_report),
has_reported = grepl('Reported:', sighting_report),
has_entered = grepl('\\(.*Entered as :', sighting_report),
has_posted = grepl('Posted:', sighting_report),
has_location = grepl('Location:', sighting_report),
has_shape = grepl('Shape:', sighting_report),
has_duration = grepl('Duration:', sighting_report)) %>%
# show_query()
count(has_occurred, has_reported, has_entered, has_posted,
has_location, has_shape, has_duration)# Source: SQL [2 x 8]
# Database: DuckDB 0.7.1 [igow@Darwin 22.5.0:R 4.2.3/:memory:]
has_occurred has_reported has_entered has_posted has_location has_shape
<lgl> <lgl> <lgl> <lgl> <lgl> <lgl>
1 TRUE TRUE TRUE TRUE TRUE TRUE
2 TRUE TRUE FALSE TRUE TRUE TRUE
# ℹ 2 more variables: has_duration <lgl>, n <dbl>ufo %>% select(sighting_report)# Source: SQL [?? x 1]
# Database: DuckDB 0.7.1 [igow@Darwin 22.5.0:R 4.2.3/:memory:]
sighting_report
<chr>
1 Occurred : (Entered as : --)Reported: 12/27/2013 2:31:11 PM 14:31Posted: 1/1…
2 Occurred : (Entered as : 2010)Reported: 3/7/2014 10:36:37 PM 22:36Posted: 3/…
3 Occurred : (Entered as : unknown)Reported: 3/21/2006 12:11:10 PM 12:11Posted…
4 Occurred : 00:00 (Entered as : 0:00)Reported: 6/15/2013 11:52:48 AM 11:52Pos…
5 Occurred : 00:00 (Entered as : 1947-2008 0:00)Reported: 2/3/2008 3:04:26 AM …
6 Occurred : 00:00 (Entered as : 20)Reported: 9/17/2012 12:14:05 PM 12:14Poste…
7 Occurred : 00:00 (Entered as : 2018 0:00)Reported: 12/18/2019 10:24:17 PM 22…
8 Occurred : 00:00 (Entered as : 5/20/20014 0:00)Reported: 4/7/2014 1:39:31 AM…
9 Occurred : 00:04 (Entered as : 00:04)Reported: 12/28/2019 3:52:42 AM 03:52Po…
10 Occurred : 00:34 (Entered as : 09/91/19 00:34)Reported: 9/1/2019 12:46:41 AM…
# ℹ more rowsregex <- paste0("Occurred :\\s*(.*)\\s*",
"Reported:\\s*(.* [AP]M).*?\\s*",
"Posted:\\s*(.*)\\s*",
"Location:\\s*(.*)\\s*",
"Shape:\\s*(.*)\\s*",
"Duration:\\s*(.*)\\s*")
regex2 <- paste0("^(.*?)",
"(?:\\s*\\(Entered as :\\s*(.*)\\))?\\s*$")
ufo_extracted <-
ufo |>
mutate(occurred_plus = regexp_extract(sighting_report, regex, 1L),
reported = regexp_extract(sighting_report, regex, 2L),
posted = regexp_extract(sighting_report, regex, 3L),
location = regexp_extract(sighting_report, regex, 4L),
shape = regexp_extract(sighting_report, regex, 5L),
duration = regexp_extract(sighting_report, regex, 6L)) |>
select(id, occurred_plus:duration) |>
mutate(occurred_raw = regexp_extract(occurred_plus, regex2, 1L),
entered = regexp_extract(occurred_plus, regex2, 1L)) |>
select(-occurred_plus) |>
mutate(location_clean = regexp_replace(location,
"(outside of|close to)", "near")) |>
mutate(reported =
case_when(reported == '' ~ NA,
nchar(reported) < 8 ~ NA,
regexp_matches(reported, "[AP]M") ~
strptime(reported, "%m/%d/%Y %I:%M:%S %p"),
TRUE ~ strptime(reported, "%m/%d/%Y %H:%M:%S")),
occurred =
case_when(occurred_raw == '' ~ NA,
nchar(occurred_raw) < 8 ~ NA,
regexp_matches(occurred_raw, "^[0-9]+/[0-9]+/[0-9]{4}$") ~
strptime(occurred_raw, "%m/%d/%Y"),
regexp_matches(occurred_raw, "[AP]M") ~
strptime(occurred_raw, "%m/%d/%Y %I:%M:%S %p"),
regexp_matches(occurred_raw, "[0-9]{2}:[0-9]{2}:[0-9]{2}") ~
strptime(occurred_raw, "%m/%d/%Y %H:%M:%S"),
TRUE ~ strptime(occurred_raw, "%m/%d/%Y %H:%M")),
posted = if_else(posted == '', NA,
as.Date(strptime(posted, "%m/%d/%Y")))) |>
collect() |>
mutate(shape = initcap(shape)) ufo_extracted |>
ggplot(aes(y = fct_rev(fct_infreq(shape)))) +
geom_bar() +
ylab("Shape")
ufo_extracted |>
filter(!is.na(occurred_raw)) |>
count(occurred_raw) |>
arrange(desc(n)) |>
slice_head(n = 10) |>
mutate(occurred_raw = fct_rev(fct_inorder(as.character(occurred_raw)))) |>
ggplot(aes(y = occurred_raw, x = n)) +
geom_bar(stat = "identity")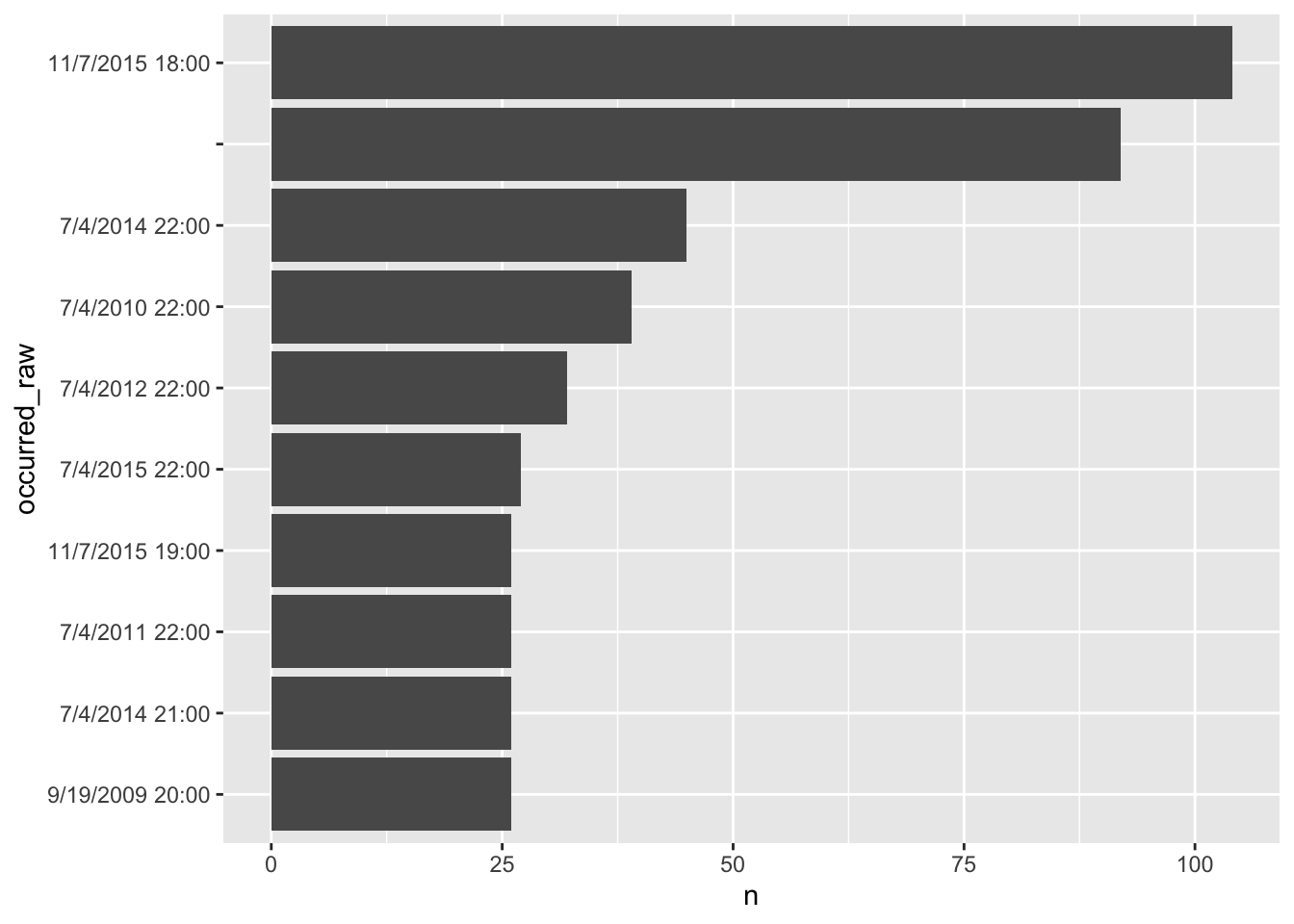
ufo_extracted |>
count(duration) |>
arrange(desc(n)) |>
slice_head(n = 10) |>
mutate(duration = fct_rev(fct_inorder(duration))) |>
ggplot(aes(y = duration, x = n)) +
geom_bar(stat = "identity")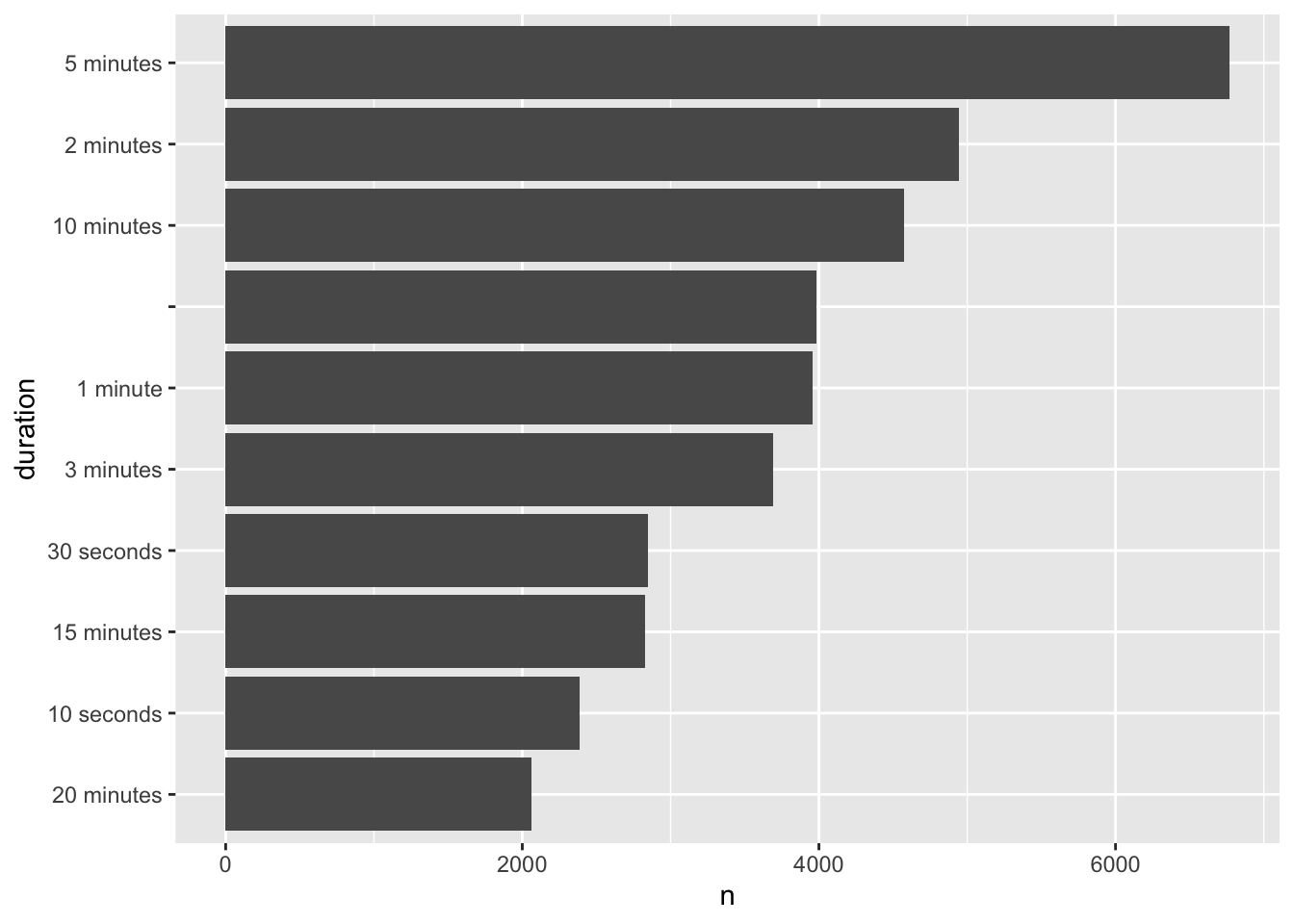
ufo_extracted |>
count(location) |>
arrange(desc(n)) |>
slice_head(n = 10) |>
mutate(location = fct_rev(fct_inorder(location))) |>
ggplot(aes(y = location, x = n)) +
geom_bar(stat = "identity")